
type
status
date
summary
tags
category
slug
icon
password
公众号
关键词
小宇宙播客
小红书
数字人视频号
笔记
[ComfyUI]Mochi:可商用!迄今最大开源视频生成模型,100亿参数&高保真动作&高提示遵循
来源公众号作者破狼
近期Genmo AI公司开源发布了最新的视频生成模型:Mochi 1 预览版。Mochi是一个开放的先进视频生成模型,具有高保真度的动作和强大的提示遵循能力。Mochi 1显著的缩小了开放视频生成模型与闭源模型之间的差距。并且以Apache 2.0开源许可发布,允许个人和企业的商业用途免费使用。当前在HuggingFace上已经开放了480p基础模型。Mochi 1 HD计划将在年底发布。另外,Genmo AI还宣布其完成了由NEA领投的2840万美元的A轮融资。
- • 在线体验:https://genmo.ai/play
- • 权重模型:https://huggingface.co/genmo/mochi-1-preview
- • github:https://github.com/genmoai/models
Mochi 1 作为领先的视频生成模型,与领先的闭源模型相比也具有较强的竞争力。当前发布的480p预览版优势如下:
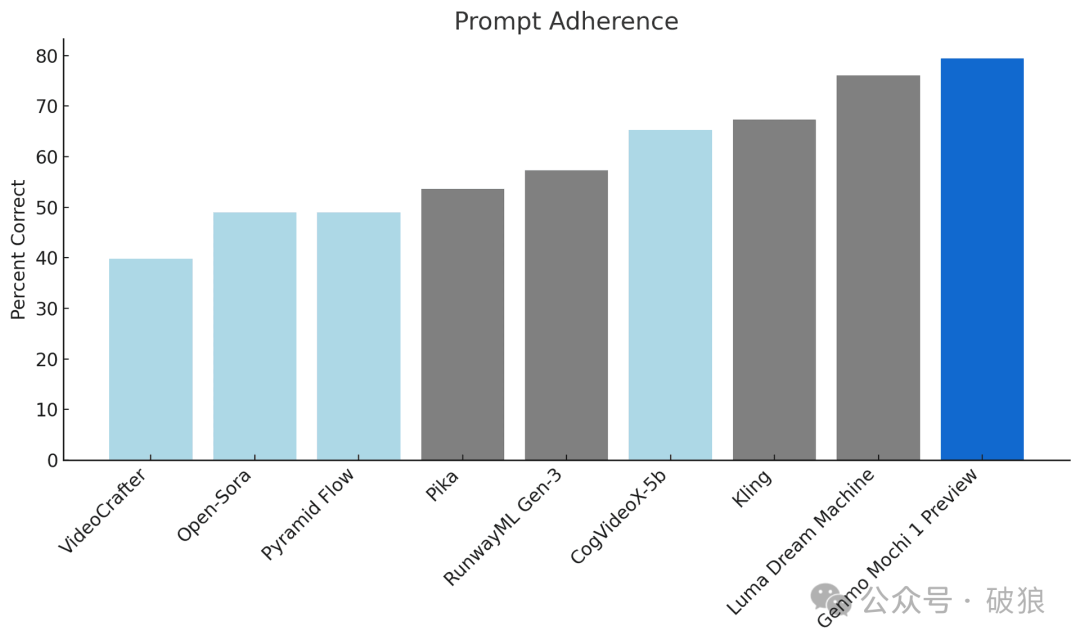
- • 提示遵循:与文本提示的对齐度极高,确保生成的视频准确反映给定的指令。这使用户能够详细控制角色、设定和动作。
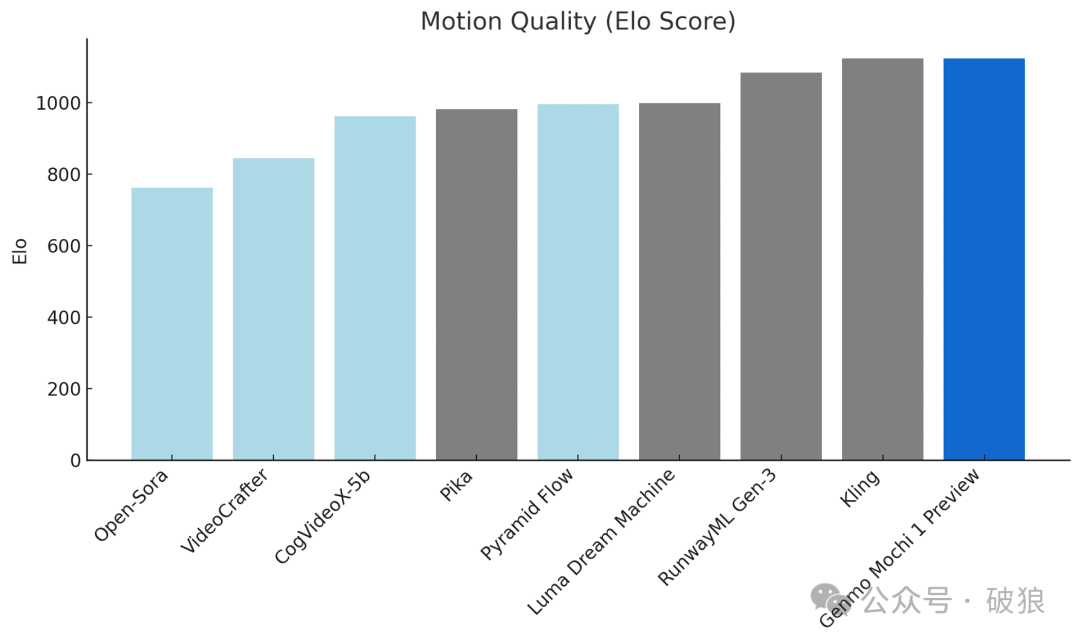
- • 动作质量:Mochi 1 以 每秒 30帧的平滑度生成长达5.4秒的视频,具有高度的时间连贯性和逼真的动作形态。
Mochi 1是采用了一个基于新颖的 非对称扩散变换器(Asymmetric Diffusion Transformer,简称 AsymmDiT)架构的100亿参数扩散模型。是迄今为止公开发布的最大的视频生成模型,并且具有架构简单、易于修改特点。
与Mochi 1一同开源的还有视频 VAE。该**VAE能够将视频压缩到原始大小的 1/12,通过 8x8的空间压缩和6x 的时间压缩,将其转换为一个 12 通道的潜在空间8。
这一过程不仅极大地减少了数据的体积,而且保留了足够的信息以便于生成模型能够在潜在空间中有效地操作。这种高效的压缩方式对于确保模型可以在资源有限的系统上运行至关重要,同时也为视频生成领域提供了一个强大的工具。
AsymmDiT 通过简化文本处理,并将神经网络的能力集中在视觉推理上,高效地处理用户提示和压缩后的视频令牌。AsymmDiT 通过多模态自注意力同时关注文本和视觉令牌,并为每种模态学习单独的 MLP 层,类似于 Stable Diffusion 3。然而,视觉流是通过更大的隐藏维度,其参数数量几乎是文本流的4倍。为了在自注意力中统一模态,Mochi使用了非正方形的 QKV 和输出投影层。这种非对称设计减少了推理时的内存需求。
与当前许多现代扩散模型使用多个预训练的语言模型来表示用户提示所不同的是:Mochi 1仅使用单个 T5-XXL 语言模型来编码提示。
Mochi 1是在完整的3D注意力下,共同推理一个包含44,520个视频令牌的上下文窗口。为了定位每个令牌,模型将可学习的旋转位置嵌入(RoPE)扩展到3个维度。网络端到端学习空间和时间轴的混合频率。
与此同时,Mochi 1还借鉴了语言模型扩展的最新进展领先技术,包括 SwiGLU 前馈层、query-key normalization以增强稳定性,以及sandwich normalization来控制内部激活。
当前版本的480p视频模型,在极端动作的边缘情况下,可能会发生轻微的形变和扭曲。Mochi 1针对逼真风格进行了优化,因此对动画内容有损失表现不佳。Genmo AI 称,本次发布的Mochi 1预览版展示了480p基础模型的能力。这只是一个开始,计划在年底前,还会发布Mochi 1 的完整版本(包括 Mochi 1 HD),。Mochi 1 HD 将支持 720p 视频生成,提高保真度,更平滑的动作,并解决复杂场景中的形变等边缘情况。
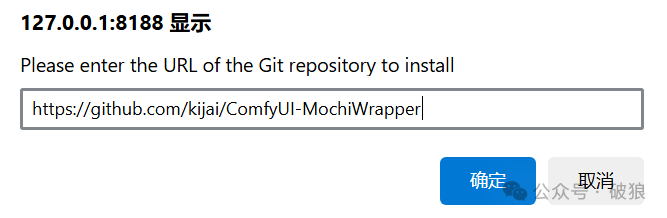
社区 @kijai 大佬已率先在ComfyUI插件ComfyUI-MochiWrapper支持Mochi的体验。首先通过插件管理器安装 ComfyUI-MochiWrapper。模型将会首次运行自动下载,如未成功下载则参考如下模型位置:
- • 插件地址: https://github.com/kijai/ComfyUI-MochiWrapper
- • t5xxl_fp8模型: 与SD3、Flux会使用想用,需放置目录ComfyUI/models/clip。地址:https://huggingface.co/mcmonkey/google_t5-v1_1-xxl_encoderonly/resolve/main/t5xxl_fp8_e4m3fn.safetensors?download=true
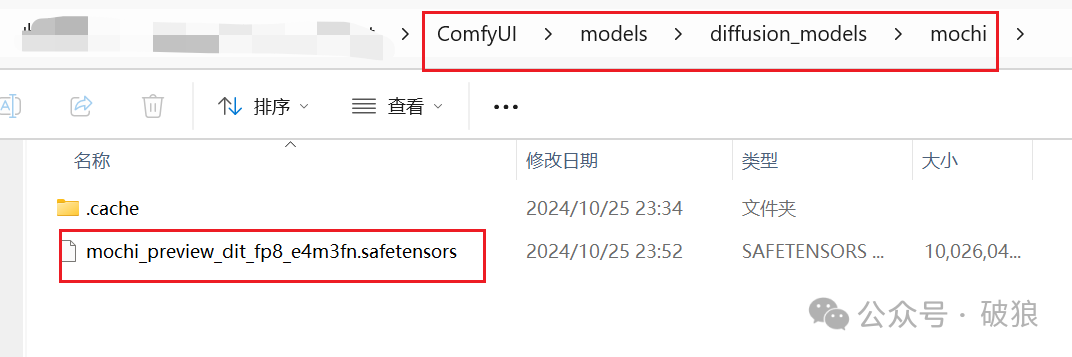
- • mochi模型: 下载模型放置目录ComfyUI/models/diffusion_models/mochi。地址:https://huggingface.co/Kijai/Mochi_preview_comfy/tree/main
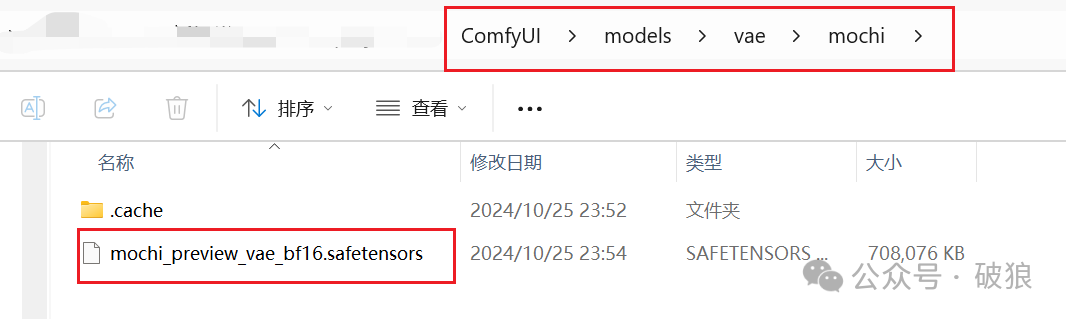
- • mochi vae模型: 下载模型放置目录ComfyUI/models/vae/mochi。地址:https://huggingface.co/genmo/mochi-1-preview/resolve/main/vae.safetensors?download=true

当前插件根据视频帧数可以容纳在20GB显存以下,其中借鉴来自CogVideoX-diffusers代码的实验性的平铺解码器,能够允许更高的帧数,作者称做的最高帧数是97,默认的平铺大小为2x2网格。为了加速也可以使用
flash_attn
, pytorch attention (sdpa)
或sage attention
, 其中sage
最快。当前工作流可LIBLIB平台下载:https://www.liblib.art/modelinfo/987eebc84cad4fa79503601bb3f7cadb?versionUuid=b7a7b0f93c7646fa9e18aeb5e9ff6ea2
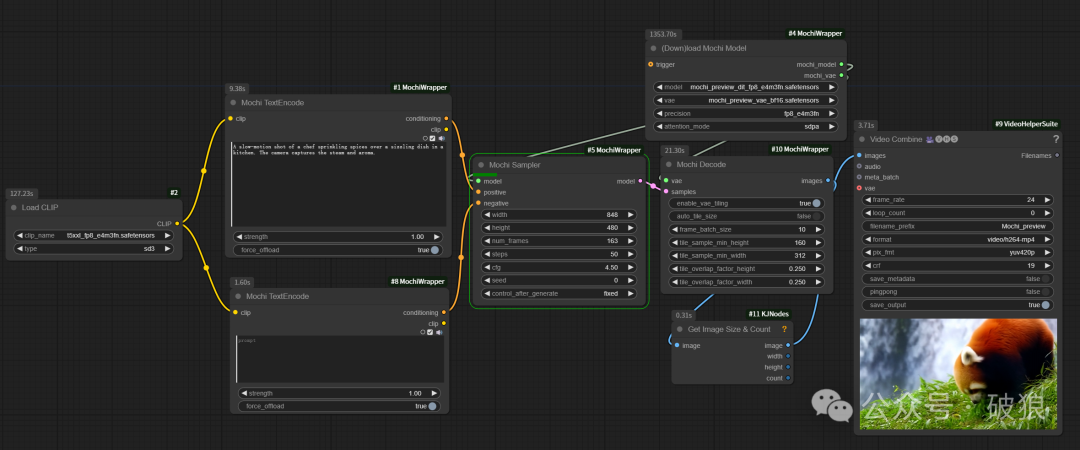

注意:整个生成过程比较耗时24G生成一个视频大约需要30分钟。
另外,LIBLIB平台已在线支持SD3.5在线工作流体验,笔者上传了支持Joy1反推+SD3.5工作流地址:https://www.liblib.art/modelinfo/fb42d5cdd58644a2b28e86e2cfd28ac0?versionUuid=1189e755690f41dc933861cc9bc0c824
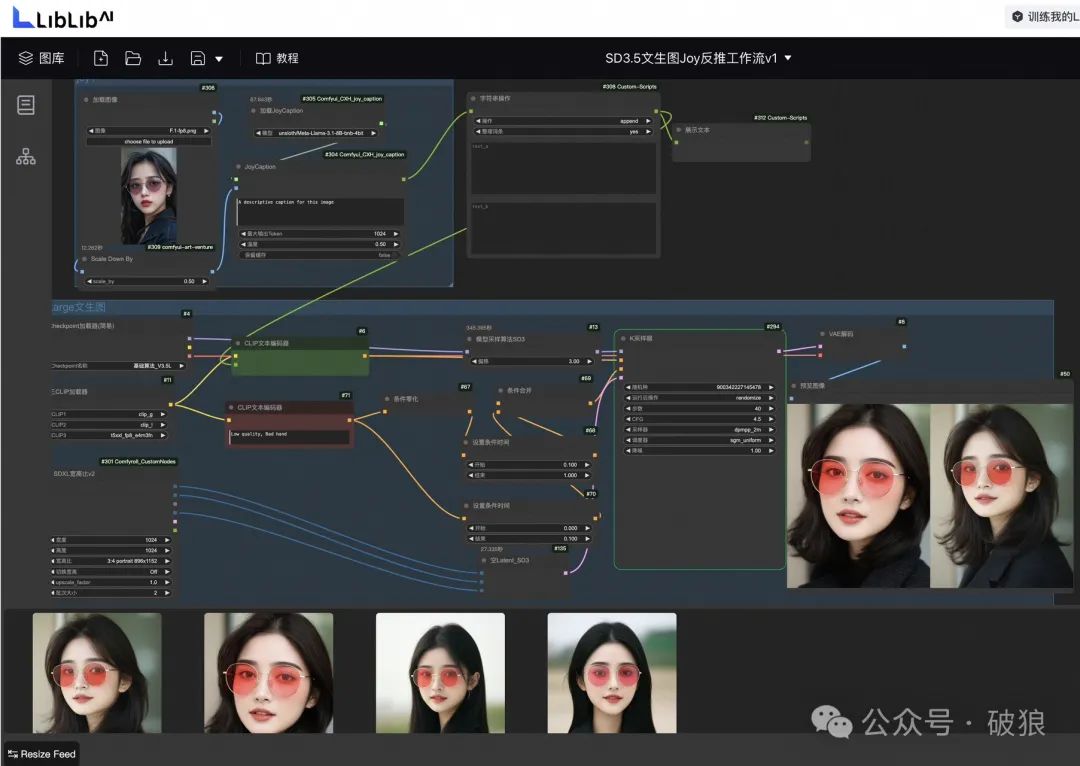
关于SD3.5质量笔者就不在此点评,感兴趣同学可以直接在线体验。关注Charliiai获得更多AI干货!
- Author:AI博士Charlii
- URL:https://www.charliiai.com//%E6%9C%80%E6%96%B0%E8%B5%84%E8%AE%AF/mochi
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!